 A shoe box or album full of photos is easy to flick through and you can quick see both its condition and content. Digital files however have limited visibility, especially a collection of digital photos. The Photo file will be in binary and unless you have specific software to decode it it will just be symbols and numbers at best. One exception is the jpeg format which is so widely used that most software, browsers, computer and smart phone apps with recognise and decently render it. Other formats and in particular the camera RAW formats will always require social software (and given that these formats are proprietary and there is a risk of them becoming obsolete) may not be guaranteed to be available on different hardware and/or in the future. Further It is unlikely that scanning the file names from the camera (like IMG_0007.CR2) will be very meaningful. You need a reader that understand the format of that data and can render it as an image. A decent catalogue (or Index) of you photos need both to be able to easily view you photos but it also benefit from some organization that makes the images quicker to find
A shoe box or album full of photos is easy to flick through and you can quick see both its condition and content. Digital files however have limited visibility, especially a collection of digital photos. The Photo file will be in binary and unless you have specific software to decode it it will just be symbols and numbers at best. One exception is the jpeg format which is so widely used that most software, browsers, computer and smart phone apps with recognise and decently render it. Other formats and in particular the camera RAW formats will always require social software (and given that these formats are proprietary and there is a risk of them becoming obsolete) may not be guaranteed to be available on different hardware and/or in the future. Further It is unlikely that scanning the file names from the camera (like IMG_0007.CR2) will be very meaningful. You need a reader that understand the format of that data and can render it as an image. A decent catalogue (or Index) of you photos need both to be able to easily view you photos but it also benefit from some organization that makes the images quicker to find
So how do you figure out what is there. There are two common solution,
- The first is Thumbnails, normally postage stamp size low resolution version that give you a peek at what is in the photo.
- The second is to use metadata (data about the context of the photo itself).
There are lots of decent (and free or inexpensive thumbnail programs) like Picasa XnView, Photo Mechanics, the default folders view in windows even lets you select a small, medium or Larger icon view, which are thumbnails. Some can handle RAW formats but other may not (or rely on updating a codex for that format). Other software like Aftershoot and OnOne 10 have a browse mode so you don’t have to “import” photos first, you just get presented with a grid of thumbnails. These are fast and a joy to use compared with opening up directories of images in say Lightroom. Having a good thumbnail facility that is fast and easy to use is the first additional need for a good archive.
Metadata, (data about the photo and it’s contents) is a little more complex but it should not be. There are two standards EXIF and IPTC metadata formats. The EXIF data is really mainly about the camera and image and has been well addressed by camera and phone manufacturers (although they may not record all the possible metadata). This EXIF metadata is included with the standard jpeg data format so the metadata travels with the image embedded in it. The IPTC Interchange Model is a way to record information about who created the photo and how it is licenced for distribution and publication (it was set up for exchange of information, and images between newspapers and is not a big deal in a personal photo archive). This information can be, but seledom is, embedded in jpeg files. Most software that works with photo will let you display both forms of this metadata. If you are having trouble reading the metadata Phil Harvey has written a wonderful open source program called ExifTool, which can interact with metadata in many formats (eg, embedded in the jpeg or stored in an .xmp sidecar file)
Whilst you can see a scratch of water stain on an old photo. It is tricker to judge damage too (corruption of a digital file) because in its raw binary digital format it if not easily comprehended. Even worse even a little damage may render the digital image unusable. There are technique to ensure digital files are not corrupted, most notable the checksums and Hash function (they 
Fortunately there are lots of well tried and tested MD5 utility and programs, many free to download. What I discovered is the best way to create these hash table is not one for each file but with one file for each sub-directory. I already had a program called total commander (and alternative to windows explorer) which does this. Further you just need to click on that file and then Total commander will scan the files mentioned and report back if the hash value matches. Yes I did a test truncating a photo and the checked reported a hash value difference. There are a number of utilities so I assume you will have no problems finding a similar one.
I have been using this approach for the past 6 months it very simple and I just create the Hash Table for each directory when I do my monthly backup checks. I have been reprocessing some older directories as I move to a hard disk based archive. Running the hash function did Identified 2 photos that had read problems, luckily I had another copy of those which was fine. I am now slowly adding hash table to all my archived photo folders.
I’m now even more certain you need to also keep a checksum or hash value, as well as an easily accessed thumbnails and standard metadata utilities in addition to your archived files. Copies of the applications used to created these views and information are an important part of your catalogue and should be stored with your archived photos.

 The biggest problem with setting up a long term digital archives related to what physical storage media you plan to use. The Digital world is littered with various storage media that have a very short operation lives and/or have fallen from common usage. I have used Punch paper tape, Punch Card, Reel to Reel Magnetic tape, Various Tape Cartridges, 8”Floppy Disk (yes they were once that big but they could hold around 1.3mb), 5¼” Floppy Disk (only 360kb), 3 ½” Rigid disk (720kb but later 1.4mb), Zip Disks (a glorious 100mb), CDs (compact disks with a capacity of around 700MB) on to DVD (which generally hold 4.7gb) and Blu-ray (which can hold up to 25gb). Unfortunately the unspoken secret here is as the capacity and specifically the information density has increased the shelf life tends to decrease. The punch paper tape for the late 60s is good to go (if only I had a reader) if it hasn’t been torn, so are the punch cards from the early 70s, but everything else has probably reached its best by date and there is a reasonable chance you will experience corruption or errors reading older media already. Even CD and DVDs, once thought invincible start to have troubles after only a few years, even less if they are not handled carefully.
The biggest problem with setting up a long term digital archives related to what physical storage media you plan to use. The Digital world is littered with various storage media that have a very short operation lives and/or have fallen from common usage. I have used Punch paper tape, Punch Card, Reel to Reel Magnetic tape, Various Tape Cartridges, 8”Floppy Disk (yes they were once that big but they could hold around 1.3mb), 5¼” Floppy Disk (only 360kb), 3 ½” Rigid disk (720kb but later 1.4mb), Zip Disks (a glorious 100mb), CDs (compact disks with a capacity of around 700MB) on to DVD (which generally hold 4.7gb) and Blu-ray (which can hold up to 25gb). Unfortunately the unspoken secret here is as the capacity and specifically the information density has increased the shelf life tends to decrease. The punch paper tape for the late 60s is good to go (if only I had a reader) if it hasn’t been torn, so are the punch cards from the early 70s, but everything else has probably reached its best by date and there is a reasonable chance you will experience corruption or errors reading older media already. Even CD and DVDs, once thought invincible start to have troubles after only a few years, even less if they are not handled carefully. 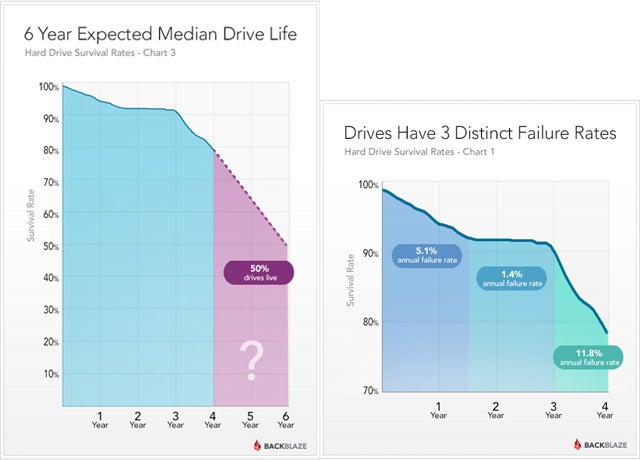 What about solid state memory (like SD memory cards, USB keys or the newer SSD drives), unfortunately they have limited life spans as well (more to do with the number of reads and writes) in normal usage they may outlast the next form of storage HDD. The conventional hard drives (whether built into your computer or as an external USB style) also have some telling untold secrets (see
What about solid state memory (like SD memory cards, USB keys or the newer SSD drives), unfortunately they have limited life spans as well (more to do with the number of reads and writes) in normal usage they may outlast the next form of storage HDD. The conventional hard drives (whether built into your computer or as an external USB style) also have some telling untold secrets (see 



